Вот как управлять потоковой передачей данных с помощью Amazon Kinesis?
Наш мир ежедневно производит огромное количество данных, поэтому любой инструмент, который может сделать обработку данных менее болезненной, станет долгожданным облегчением. К счастью, доступно множество инструментов и услуг для обработки данных.
Итак, сегодня мы сосредоточимся на Amazon Kinesis. Мы рассмотрим, что такое Amazon Kinesis, а также его использование, ограничения, преимущества и функции. Мы также рассмотрим потоки данных Amazon Kinesis, объясним аналитику данных kinesis и сравним Kinesis с другими ресурсами, такими как SQS, SNS и Kafka.
Итак, что же такое Amazon Kinesis?
Что такое Amazon Kinesis?
Amazon Kinesis — это серия управляемых облачных сервисов, предназначенных для сбора и обработки потоковых данных в режиме реального времени. Цитируя Веб-страница AWS Kinesis«Amazon Kinesis упрощает сбор, обработку и анализ потоковых данных в режиме реального времени, чтобы вы могли получать своевременную информацию и быстро реагировать на новую информацию. Amazon Kinesis предлагает ключевые возможности для экономичной обработки потоковых данных в любом масштабе, а также гибкость в выборе инструментов, которые лучше всего соответствуют требованиям вашего приложения. С помощью Amazon Kinesis вы можете получать данные в реальном времени, такие как видео, аудио, журналы приложений, потоки посещений веб-сайтов и данные телеметрии Интернета вещей, для машинного обучения, аналитики и других приложений. Amazon Kinesis позволяет вам обрабатывать и анализировать данные по мере их поступления и мгновенно реагировать вместо того, чтобы ждать, пока все ваши данные будут собраны, прежде чем можно будет начать обработку».
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)
Amazon Kinesis состоит из четырех специализированных сервисов или возможностей:
- Kinesis Data Streams (KDS): Amazon Kinesis Data Streams собирает потоковые данные, генерируемые различными источниками данных, в режиме реального времени. Затем приложения-производители записывают данные в поток данных Kinesis, а приложения-потребители, подключенные к потоку, считывают данные для различных типов обработки.
- Kinesis Data Firehose (KDF): эта услуга исключает необходимость написания приложений или управления ресурсами. Пользователи настраивают производителей данных для отправки данных в Kinesis Data Firehose, который автоматически доставляет данные в указанные места назначения. Пользователи могут даже настроить Kinesis Data Firehose для изменения данных перед их отправкой.
- Kinesis Data Analytics (KDA): этот сервис позволяет пользователям обрабатывать и анализировать потоковые данные. Он обеспечивает масштабируемую и эффективную среду, в которой выполняются приложения, созданные с использованием инфраструктуры Apache Flink. Кроме того, платформа предлагает полезные операторы, такие как агрегат, фильтр, карта, окно и т. д., для запроса потоковых данных.
- Kinesis Video Streams (KVS): это полностью управляемый сервис, используемый для потоковой передачи медиафайлов в реальном времени с устройств захвата аудио или видео в облако AWS. Он также может создавать приложения для обработки видео в реальном времени и пакетной видеоаналитики.
Подробнее каждую услугу мы рассмотрим позже.
Каковы ограничения Amazon Kinesis?
Хотя приведенное выше описание звучит впечатляюще, даже у Kinesis есть ограничения и ограничения. Например:
- Доступ к записям потока по умолчанию возможен в течение 24 часов, а при включении расширенного срока хранения данных его можно продлить до семи дней.
- По умолчанию вы можете создать до 50 потоков данных в режиме мощности по требованию в своей учетной записи Amazon Web Services. Если вам необходимо увеличить квоту, вам необходимо обратиться в службу поддержки AWS.
- Максимальный размер полезных данных до кодирования Base64 (также называемый большим двоичным объектом данных) в одной записи составляет один мегабайт (МБ).
- Вы можете переключаться между режимами предоставления мощности по требованию и предоставленной мощности для каждого потока данных в вашей учетной записи дважды в течение 24 часов.
- Один шард поддерживает до 1000 записей PUT в секунду, а каждый шард поддерживает до пяти транзакций чтения в секунду.
Как вы используете Amazon Kinesis?
Amazon Kinesis легко настроить. Выполните следующие действия:
- Настроить Кинезис
- Войдите в свою учетную запись AWS, затем выберите Amazon Kinesis в консоли управления Amazon.
- Нажмите на кнопку «Создать поток» и заполните все необходимые поля. Затем нажмите кнопку «Создать».
- Теперь вы увидите поток в списке потоков.
- Настройка пользователей. Этот этап включает в себя использование функции «Создать новых пользователей» и назначение политик каждому из них.
- Подключите Kinesis к вашему приложению. В зависимости от вашего приложения (Looker, Tableau Server, Domo, ZoomData) вам, вероятно, потребуется обратиться к окнам «Настройки» или «Администратор» и следовать подсказкам, обычно в разделе «Источники».
Каковы особенности Amazon Kinesis?
Вот наиболее выдающиеся особенности Amazon Kinesis:
- Это экономически выгодно: Kinesis использует модель оплаты по мере использования необходимых вам ресурсов и взимает почасовую плату за требуемую пропускную способность.
- Его легко использовать: вы можете быстро создавать новые потоки, устанавливать требования и начинать потоковую передачу данных.
- Вы можете создавать приложения Kinesis: разработчики получают клиентские библиотеки, которые позволяют им разрабатывать и использовать приложения для обработки данных в реальном времени.
- Он безопасен: вы можете защитить свои хранящиеся данные, используя шифрование на стороне сервера и главные ключи AWS KMS для любых конфиденциальных данных в потоках данных Kinesis. Вы можете получить доступ к данным конфиденциально через виртуальное частное облако Amazon (VPC).
- Он отличается гибкостью, высокой пропускной способностью и обработкой в реальном времени: Kinesis позволяет пользователям собирать и анализировать информацию в режиме реального времени, а не ждать отчета о выводе данных.
- Он интегрируется с другими сервисами Amazon: например, Kinesis интегрируется с Amazon DynamoDB, Amazon Redshift и Amazon S3.
- Он полностью управляем: Kinesis полностью управляем, поэтому он запускает ваши потоковые приложения без необходимости управлять какой-либо инфраструктурой.
Все о потоках данных Kinesis (KDS)
Amazon Kinesis Data Streams собирает и хранит потоковые данные в режиме реального времени. Потоковые данные собираются из разных источников приложениями-производителями из разных источников, а затем непрерывно передаются в поток данных Kinesis. Кроме того, потребительские приложения могут считывать данные из KDS и обрабатывать их в режиме реального времени.
По умолчанию данные, хранящиеся в Kinesis Data Stream, хранятся 24 часа, но их можно изменить на срок до 365 дней.
В рамках обработки потребительские приложения могут сохранять результаты с помощью других сервисов AWS, таких как DynamoDB, Redshift или S3. Кроме того, эти приложения обрабатывают данные в реальном или близком к реальному времени, что делает сервис Kinesis Data Streams особенно ценным для создания чувствительных ко времени приложений, таких как обнаружение аномалий или информационные панели в реальном времени.
KDS также используется для агрегации данных в реальном времени с последующей загрузкой агрегированных данных в хранилище данных или кластер с сокращением карты.
Определение потоков, сегментов и записей
Поток состоит из нескольких носителей данных, называемых осколками. Общая емкость потока данных представляет собой сумму мощностей всех составляющих его сегментов. Каждый осколок предоставляет установленное значение емкости и имеет последовательность записей данных. Данные, хранящиеся в сегменте, называются записью; каждый осколок имеет ряд записей данных. Каждой записи данных присваивается порядковый номер, присвоенный потоком данных Kinesis.
Создание потока данных Kinesis
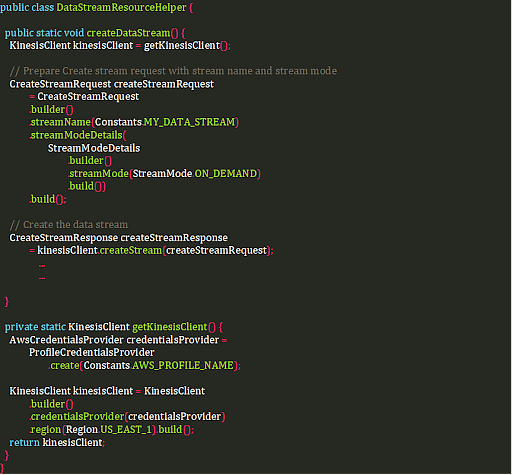
Вы можете создать поток данных Kinesis из интерфейса командной строки AWS (CLI) или с помощью консоли управления AWS Kinesis Data Streams, используя операцию CreateStream API Kinesis Data Streams из AWS SDK. Вы также можете использовать AWS CloudFormation или AWS CDK для создания потока данных в рамках проекта «инфраструктура как код».
Для наглядности приведем пример кода. В этом примере создается поток данных с помощью API Kinesis Data Streams, включая режим «по требованию».
Записи потоков данных Kinesis
Эти записи имеют:
- Порядковый номер: уникальный идентификатор, присваиваемый KDS каждой записи.
- Ключ раздела: этот ключ разделяет и направляет записи в разные сегменты в потоке.
- Большой двоичный объект данных: максимальный размер большого двоичного объекта составляет 1 мегабайт.
Прием данных: запись данных в потоки данных Kinesis
Приложения, записывающие данные в потоки KDS, называются «производителями». Пользователи могут создавать собственные приложения-производители на поддерживаемом языке программирования с помощью AWS SDK или библиотеки Kinesis Producer Library (KPL). Пользователи также могут использовать Kinesis Agent — автономное приложение, которое работает в качестве агента в серверных средах на базе Linux, таких как серверы баз данных, серверы журналов и веб-серверы.
Потребление данных: чтение данных из потоков данных Kinesis
Этот этап включает в себя создание потребительского приложения, которое обрабатывает данные из потока данных.
Потребители потоков данных Kinesis
API Kinesis Data Streams — это низкоуровневый метод чтения потоковых данных. Пользователи должны опрашивать поток, проверять обработанные записи, запускать несколько экземпляров и выполнять другие задачи с помощью Kinesis Data Streams API для выполнения операций с потоком данных. В результате практично создать потребительское приложение для чтения потоковых данных. Вот пример возможных применений:
- AWS Лямбда
- Клиентская библиотека Kinesis (KCL)
- Пожарный шланг данных Kinesis
- Аналитика данных Кинезиса
Ограничения пропускной способности: общие и расширенные потребители с разветвлением
Пользователи должны учитывать ограничения пропускной способности Kinesis Data Stream при проектировании и эксплуатации очень надежной системы потоковой передачи данных и обеспечении предсказуемой производительности.
Помните, что емкость потока данных является функцией количества сегментов в потоке, а сегмент поддерживает пропускную способность 1 МБ в секунду и 1000 записей в секунду для пропускной способности записи и 2 МБ в секунду для пропускной способности чтения. Когда несколько потребителей читают данные из сегмента, эта пропускная способность чтения распределяется между ними. Эти потребители известны как «общие разветвленные потребители». Однако если пользователям нужна выделенная пропускная способность для своих потребителей, они могут определить последних как «потребителей с расширенным разветвлением».
Пожарный шланг данных Kinesis
Kinesis Data Firehose — это полностью управляемый сервис и самый простой способ загрузки потоковых данных в хранилища данных и инструменты аналитики. Пожарный шланг собирает, преобразует и загружает потоковые данные и позволяет проводить аналитику практически в реальном времени при использовании существующих инструментов бизнес-аналитики (BI) и информационных панелей.
Создание потока доставки Kinesis Firehose
Вы можете создать поток доставки Firehose, используя AWS SDK, консоль управления AWS или инфраструктуру как услугу, например AWS CloudFormation и AWS CDK.
Передача данных в поток доставки Kinesis Firehose
Вы можете отправлять данные в пожарный шланг из нескольких разных источников:
- Поток данных Kinesis
- Агент Kinesis Firehose
- API Kinesis Data Firehose
- Журналы Amazon CloudWatch
- События CloudWatch
- AWS IoT как источник данных
Объяснение преобразования данных в потоке доставки «пожарного шланга»
Пользователи могут настроить поток доставки Kinesis Data Firehose, преобразовывая и конвертируя потоковые данные из источника данных перед доставкой преобразованных данных в пункт назначения с помощью этих двух методов:
- Преобразование входящих данных
- Преобразование формата записей входящих данных.
Формат доставки данных потока пожарной доставки
После того как поток доставки получает потоковые данные, они автоматически доставляются в настроенное место назначения. Каждый тип места назначения, поддерживаемый Kinesis Data Firehose, имеет свою особую конфигурацию доставки данных.
Объяснение аналитики данных Kinesis
Kinesis Data Analytics — это самый простой способ анализа и обработки потоковых данных в реальном времени. Он предоставляет информационные панели в реальном времени, генерирует аналитику временных рядов и создает уведомления и оповещения в реальном времени.
В чем разница между потоками данных Amazon Kinesis и аналитикой данных Kinesis?
Мы используем Kinesis Data Streams для написания потребительских приложений со специальным кодом, предназначенным для выполнения любой необходимой потоковой обработки данных. Однако эти приложения обычно работают на экземплярах серверов, таких как EC2, в инфраструктуре, которую мы предоставляем и управляем. С другой стороны, Kinesis Data Analytics предоставляет автоматически подготавливаемую среду, предназначенную для запуска приложений, созданных с использованием платформы Flink, которая автоматически масштабируется для обработки любого объема входящих данных.
Кроме того, потребительские приложения Kinesis Data Streams обычно записывают записи в такое место назначения, как корзина S3 или таблица DynamoDB, после завершения некоторой обработки. Однако в Kinesis Data Analytics есть приложения, которые выполняют такие запросы, как агрегирование и фильтрацию, применяя различные окна к потоковым данным. Этот процесс определяет тенденции и закономерности для оповещений в реальном времени и каналов информационной панели.
Структура приложения Flink
Приложения Flink состоят из:
- Среда выполнения: эта среда определена в основном классе приложения и отвечает за создание конвейера данных, который содержит бизнес-логику и состоит из одного или нескольких операторов, связанных вместе.
- Источник данных. Приложение получает данные, обращаясь к источнику, а соединитель источника считывает данные из потока данных Kinesis, корзины Amazon S3 или других подобных ресурсов.
- Операторы обработки. Приложение обрабатывает данные, используя операторы обработки, преобразуя входные данные, поступающие из источников данных. После завершения преобразования приложение пересылает измененные данные в приемники данных.
- Приемник данных: приложение генерирует данные во внешние источники, используя приемники. Соединители приемника записывают данные в поток доставки Kinesis Data Firehose, поток данных Kinesis, корзину Amazon S3 или другое подобное место назначения.
Создание приложения Flink
Пользователи создают приложения Flink и запускают их с помощью сервиса Kinesis Data Analytics. Пользователи могут создавать эти приложения на Java, Python или Scala.
Настройка потока данных Kinesis как источника и приемника
После тестирования конвейера данных пользователи могут изменить источник данных в коде, чтобы он подключался к потоку данных Kinesis, который принимает потоковые данные, которые необходимо обработать.
Развертывание приложения Flink в Kinesis Data Analytics
Kinesis Data Analytics создает задания для запуска приложений Flink. Задания ищут скомпилированный исходный код в корзине S3. Таким образом, после компиляции и упаковки приложения пользователи должны создать приложение в Kinesis Data Analytics, настроив следующие компоненты:
- Входные данные: пользователи сопоставляют источник потоковой передачи с потоком данных внутри приложения, и данные передаются из нескольких источников данных в поток данных внутри приложения.
- Код приложения: этот элемент состоит из местоположения корзины S3, в которой находится скомпилированное приложение Flink. Приложение считывает поток данных внутри приложения, связанный с источником потоковой передачи, а затем записывает в поток данных внутри приложения, связанный с выводом.
- Вывод: этот компонент состоит из одного или нескольких потоков внутри приложения, в которых хранятся промежуточные результаты. Затем пользователи могут дополнительно настроить выходные данные приложения для сохранения данных из определенных потоков внутри приложения и отправки их во внешнее место назначения.
Использование создания заданий для запуска приложения Kinesis Data Analytics
Пользователи могут запустить приложение, выбрав «Запустить» на странице приложения в консоли AWS. Когда пользователи запускают приложение Kinesis Data Analytics, служба Kinesis Data Analytics создает задание Apache Flink. Диспетчер заданий управляет выполнением задания и ресурсами, которые оно использует. Он также разделяет реализацию приложения на задачи, а диспетчер задач, в свою очередь, контролирует каждую задачу. Пользователи контролируют производительность приложений, проверяя производительность каждого диспетчера задач или диспетчера заданий.
Создание приложения Flink в интерактивном режиме с помощью ноутбуков
Пользователи могут использовать блокноты — инструмент, который обычно используется в задачах по обработке данных, — для создания приложений Flink. Блокнот определяется как интерактивная веб-среда разработки, используемая специалистами по данным для написания и выполнения кода, а также визуализации результатов. Блокноты Studio можно создавать в Консоли управления AWS.
Все о видеопотоках Kinesis (KVS)
Kinesis Video Stream определяется как полностью управляемый сервис, используемый для:
- Подключайте и транслируйте аудио, видео и другие данные с временным кодированием с различных устройств захвата. В этом процессе используется инфраструктура, динамически предоставляемая в облаке AWS.
- Создавайте приложения, которые работают с потоками данных в реальном времени, используя полученные данные покадрово и в режиме реального времени для обработки с малой задержкой.
- Надежно и надежно храните любые мультимедийные данные в течение срока хранения по умолчанию от одного дня до 10 лет.
- Создавайте специальные или пакетные приложения, которые работают с долговременно сохраняемыми данными без строгих требований к задержке.
Ключевые понятия: производитель, потребитель и видеопоток Kinesis.
Служба построена на идее, что производитель отправляет потоковые данные в поток, а затем потребительское приложение считывает переданные данные из потока. Главными понятиями являются:
- Продюсер: это может быть любое устройство, генерирующее видео, например камера видеонаблюдения, нательная камера, камера смартфона или камера на приборной панели. Производители также могут отправлять невидеоданные, такие как изображения, аудиоканалы или данные RADAR. По сути, это любой источник, который помещает данные в видеопоток.
- Kinesis Video Stream: этот ресурс передает видеоданные в реальном времени, при необходимости сохраняет их, а затем делает информацию доступной для использования в режиме реального времени, на разовой или пакетной основе.
- Потребитель: Потребитель — это приложение, которое считывает фрагменты и кадры из KVS для просмотра, обработки или анализа.
Создание видеопотока Kinesis
Пользователи могут создать видеопоток Kinesis с помощью консоли администратора AWS.
Отправка медиаданных в видеопоток Kinesis
Затем пользователи должны настроить продюсера для размещения данных в видеопотоке Kinesis. Продюсер использует SDK Kinesis Video Streams Producer, который извлекает видеоданные (в виде кадров) из медиа-источников и загружает их в KVS. Это действие выполняет все основные задачи, необходимые для упаковки фрагментов и кадров, созданных медиаконвейером устройства. SDK также может обрабатывать ротацию токенов для безопасной и бесперебойной потоковой передачи, создания потока, обработки подтверждений, возвращаемых Kinesis Video Streams, и других задач.
Использование медиаданных из видеопотока Kinesis
Наконец, пользователи используют медиаданные, просматривая их в консоли AWS Kinesis Video Stream или создавая приложение, которое может считывать медиаданные из Kinesis Video Stream. Библиотека анализатора видеопотока Kinesis — это набор инструментов, используемый в приложениях Java для использования данных MKV из видеопотока Kinesis.
Apache Kafka против AWS Kinesis
И Kafka, и Kinesis предназначены для приема и обработки нескольких крупномасштабных потоков данных из разрозненных и гибких источников. Обе платформы заменяют традиционные брокеры сообщений, поглощая большие потоки данных, которые необходимо обрабатывать и доставлять различным службам и приложениям.
Наиболее существенное различие между Kinesis и Kafka заключается в том, что последний представляет собой управляемый сервис, требующий лишь минимальной настройки и настройки. С другой стороны, Kafka — это решение с открытым исходным кодом, для настройки которого требуется много инвестиций и знаний, обычно установка занимает недели, а не часы.
Amazon Kinesis использует такие важные понятия, как производители данных, потребители данных, записи данных, потоки данных, сегменты, ключ раздела и порядковые номера. Как мы уже видели, он состоит из четырех специализированных сервисов.
Однако Kafka использует брокеров, потребителей, записи, производителей, журналы, разделы, темы и кластеры. Кроме того, Kafka состоит из пяти основных API:
- API-интерфейс Producer позволяет приложениям отправлять потоки данных в темы в кластере Kafka.
- Consumer API позволяет приложениям читать потоки данных из тем в кластере Kafka.
- API Streams преобразует потоки данных из входных тем в выходные темы.
- API Connect позволяет реализовать соединители для постоянного извлечения данных из какой-либо исходной системы или приложения в Kafka или для передачи из Kafka в некоторую систему-приемник или приложение.
- API AdminClient позволяет управлять и проверять брокеров, темы и другие объекты, связанные с Kafka.
Кроме того, Kafka предлагает поддержку SDK для Java, а Kinesis поддерживает Android, Java, Go и .Net, а также другие. Kafka более гибок, позволяя пользователям лучше контролировать детали конфигурации. Однако жесткость Kinesis является особенностью, поскольку эта негибкость означает стандартизированную конфигурацию, что, в свою очередь, обеспечивает быстрое время установки.
SQS против SNS против Kinesis
Вот краткое сравнение SQS (Amazon Simple Queue Service), SNS (Amazon Simple Notification Service) и Kinesis:
СКС | социальные сети | Кинезис |
Потребители извлекают данные. | Рассылает данные множеству подписчиков. | Потребители извлекают данные. |
Данные удаляются после использования. | Вы можете иметь до 10 000 000 подписчиков. | Вы можете иметь столько потребителей, сколько вам нужно. |
Вы можете иметь столько работников (или потребителей), сколько вам нужно. | Данные не сохраняются, то есть они теряются, если не удаляются. | Возможно воспроизведение данных. |
Нет необходимости обеспечивать пропускную способность. | Он имеет до 10 000 000 тем. | Он предназначен для обработки больших данных, аналитики и ETL в режиме реального времени. |
Нет гарантии заказа, за исключением очередей FIFO. | Нет необходимости обеспечивать пропускную способность. | Срок действия данных истекает через определенное количество дней. |
Задержка индивидуального сообщения | Он интегрируется с SQS для создания разветвленной архитектуры. | Вы должны обеспечить пропускную способность. |
Наша программа Data Engineering PG реализуется в рамках живых сессий, отраслевых проектов, мастер-классов, хакатонов IBM, сеансов «Спроси меня о чем угодно» и многого другого. Если вы хотите продвинуться в карьере инженера данных, зарегистрируйтесь прямо сейчас!
Вы хотите стать инженером данных?
Если вас интересует перспектива работы с данными способами, подобными тем, которые мы показали выше, вам может понравиться карьера в области разработки данных! Simplilearn предлагает последипломную программу по инженерии данных, проводимую в партнерстве с Университетом Пердью и в сотрудничестве с IBM, которая поможет вам овладеть всеми важными навыками инженерии данных.
Этот учебный курс идеально подходит для профессионалов и охватывает такие важные темы, как платформа Hadoop, обработка данных с использованием Spark, конвейеры данных с Kafka, большие данные на AWS и облачные инфраструктуры Azure. Simplilearn реализует эту программу посредством живых сессий, отраслевых проектов, мастер-классов, хакатонов IBM и сеансов Ask Me Anything.
Стеклянная дверь сообщает, что инженер по обработке данных в США может зарабатывать в среднем 117 476 долларов в год.
Итак, посетите Simplilearn сегодня и начните сложную, но полезную новую карьеру!
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)

