Шпаргалка по Scikit Learn: полный глоссарий Scikit Learn
Если вы программист Python, ищущий надежную библиотеку для создания моделей машинного обучения, то библиотека, которую вы захотите серьезно рассмотреть, — это scikit-learn. В этой шпаргалке по scikit learn вы получите обзор некоторых наиболее распространенных функций и инструментов, доступных в библиотеке scikit-learn, и эта шпаргалка по scikit learn будет работать как ваш go to scikit learn глоссарий.
Станьте экспертом в области науки о данных и получите работу своей мечтыПрограмма аспирантуры Калифорнийского технологического института по науке о данныхИзучить программу![]()
Шпаргалка по Scikit Learn
В этой шпаргалке по scikit learn вы узнаете о:
- Scikit Learn Tool (надежная библиотека, доступная на Python)
- Загрузка набора данных (различные способы загрузки данных в Scikit изучаются перед построением моделей)
- Представление данных (различные способы представления данных в Scikit Learn)
- Estimator API (один из основных API, реализованных Scikit-learn)
Линейная регрессия (для расширения линейных моделей)
- Стохастический градиентный спуск (метод оптимизации для обучения моделей)
- Обнаружение аномалий (для выявления точек данных, которые не соответствуют остальным данным в наборе данных)
- Обучение KNN (K-ближайший сосед (KNN) — простой алгоритм машинного обучения)
- Методы усиления (для построения ансамблевой модели пошаговым способом)
Методы кластеризации (для поиска закономерностей среди выборок данных и объединения их в группы)
Scikit Learn — одна из самых популярных и надежных библиотек, доступных на Python. Она предоставляет ряд эффективных инструментов для машинного обучения и статистического моделирования. Сюда входят регрессия, кластеризация, классификация и снижение размерности через последовательный интерфейс на Python. Библиотека в основном написана на Python, но построена на NumPy, SciPy и Matplotlib.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)
Загрузка набора данных
Чтобы построить модели машинного обучения, вам необходимо сначала загрузить данные в память.
Упакованные наборы данных
Библиотека Scikit Learn поставляется с большим количеством упакованных наборов данных. Эти наборы данных полезны для получения информации о заданном алгоритме или библиотечной функции перед построением ваших моделей.
Загрузить из CSV
Если у вас есть набор данных в виде CSV-файла на локальной рабочей станции или на удаленном сервере, вы также можете загрузить его напрямую в Scikit Learn. Из подготовленных переменных X и Y вы можете начать обучение модели машинного обучения.
Представление данных
Scikit Learn предлагает несколько способов представления данных — например, таблицы, матрицы признаков или целевые массивы.
Данные в виде таблиц
Таблицы — лучший способ представления данных в Scikit-learn. Они состоят из двумерной сетки данных со строками, представляющими отдельные элементы набора данных, и столбцами, представляющими величины, связанные с этими отдельными элементами.
Данные как матрица признаков
Матрица признаков — это табличная структура, которая хранится в переменной X и предполагается двумерной с формой (n_samples, n_features). Она в основном содержится в массиве NumPy или Pandas DataFrame. Как и в таблице, отдельные объекты описываются набором данных, а признаки представляют собой отдельные наблюдения, которые количественно описывают каждый образец.
Данные как целевой массив
Целевой массив или метка обозначается переменной Y. Обычно это 1D с длиной n_samples. Он в основном содержится в массиве NumPy или Pandas Series. Целевые массивы могут содержать как непрерывные числовые, так и дискретные значения.
Станьте экспертом в области науки о данных и получите работу своей мечтыПрограмма аспирантуры Калифорнийского технологического института по науке о данныхИзучить программу![]()
API оценщика
Estimator API — один из основных API, реализованных Scikit-learn. Он обеспечивает согласованный интерфейс для широкого спектра приложений машинного обучения, поэтому все алгоритмы машинного обучения в Scikit-Learn реализованы через Estimator API. Объект, который обучается на данных (подгоняет данные), является оценщиком. Его можно использовать с любым алгоритмом, таким как классификация, регрессия, кластеризация или даже с трансформатором, который извлекает полезные признаки из необработанных данных.
Обобщенная линейная регрессия
Обобщенные линейные модели (GLM) расширяют линейные модели двумя способами. Сначала прогнозируемые значения связываются с линейной комбинацией входных переменных с помощью функции обратной связи.

Затем квадратичная функция потерь заменяется единичным отклонением распределения в экспоненциальном семействе.
Задача минимизации, таким образом, состоит в следующем:
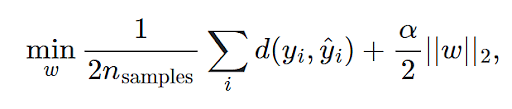
Где α — штраф регуляризации L2.
В следующей таблице приведены некоторые конкретные EDM и их единичные отклонения.
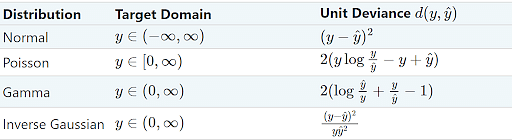
Стохастический градиентный спуск
Стохастический градиентный спуск (SGD) — это метод оптимизации, который позволяет тренировать модели машинного обучения. Его можно применять к крупномасштабным и разреженным задачам машинного обучения, которые часто встречаются при классификации текста и обработке естественного языка.
Преимущества SGD:
- Эффективный
- Простота реализации (множество возможностей для настройки кода).
Недостатки SGD:
- Требуется ряд гиперпараметров
- Чувствителен к масштабированию признаков
Обнаружение аномалий
Обнаружение аномалий используется для определения точек данных, которые не соответствуют остальным данным в наборе данных. Аномалии или выбросы можно разделить на три категории:
- Точечные аномалии — возникают, если отдельный экземпляр данных считается аномальным по отношению к остальным данным.
- Контекстные аномалии. Возникают, если экземпляр данных является аномальным в определенном контексте.
- Коллективные аномалии. Возникают, если совокупность связанных экземпляров данных является аномальной по отношению ко всему набору данных, а не к отдельным значениям.
Для обнаружения аномалий используются два метода: обнаружение выбросов и обнаружение новизны:
SНет | Метод | Описание |
1 | Обнаружение выбросов |
|
2 | Обнаружение новизны |
|
Обучение КНН
K-Nearest Neighbor (KNN) — один из самых простых алгоритмов машинного обучения. Он не требует никаких точек обучающих данных; все обучающие данные используются на этапе тестирования. Алгоритм k-NN состоит из двух шагов:
Шаг 1: Вычислить и сохранить k ближайших соседей для каждого образца в обучающем наборе.
Шаг 2: Извлечь k ближайших соседей из набора данных. Среди этих k-ближайших соседей предсказать класс путем голосования.
Модуль sklearn.neighbors обеспечивает функциональность для неконтролируемых и контролируемых методов обучения KNN.
Неконтролируемое обучение KNN
Модуль sklearn.neighbors.NearestNeighbors используется для реализации неконтролируемого обучения KNN. В этом модуле используются следующие параметры.
SНет | Параметр | Описание |
1 | n_neighbors − int, необязательно |
|
2 | радиус − float, необязательно |
|
3 | алгоритм − {'auto', 'ball_tree', 'kd_tree', 'brute'}, необязательно |
|
4 | leaf_size − int, необязательно |
|
5 | метрика − строка или вызываемая |
|
6 | P − целое число, необязательно |
|
7 | metric_params − dict, необязательно |
|
8 | N_jobs − int или None, необязательно |
|
Контролируемое обучение KNN
Обучение KNN с учителем используется для классификации (для данных с дискретными метками) и регрессии (для данных с непрерывными метками). Существуют два различных типа классификаторов ближайшего соседа, используемых scikit-learn:
SНет | Классификаторы | Описание |
1. |
| |
2. |
|
Станьте экспертом в области науки о данных и получите работу своей мечтыПрограмма аспирантуры Калифорнийского технологического института по науке о данныхИзучить программу![]()
Методы повышения
Методы повышения помогают вам построить модель ансамбля инкрементальным способом, обучая последовательно каждый оценщик базовой модели. Модуль sklearn.ensemble имеет два метода повышения – AdaBoost и Gradient Tree Boosting.
АдаБуст
AdaBoost — очень успешный метод ансамблевого усиления, который присваивает веса экземплярам в наборе данных.
Классификация с AdaBoost
Sklearn.ensemble.AdaBoostClassifier используется для построения классификатора в AdaBoost. Основным параметром этого модуля является base_estimator, который является значением базовой оценки, из которой строится усиленный ансамбль. Если мы установим значение этого параметра на «none», то базовой оценкой будет DecisionTreeClassifier(max_depth=1).
Усиление градиентного дерева
Gradient Tree Boost — это обобщение бустинга для произвольных дифференцируемых функций потерь. Его можно использовать для любого типа регрессии и задачи классификации. Главное преимущество градиентного древовидного бустинга заключается в том, что он может обрабатывать данные смешанного типа.
Классификация с градиентным усилением дерева
Для построения классификатора в Gradient Tree Boost используется sklearn.ensemble.GradientBoostingClassifier. Основным параметром этого модуля является 'loss', представляющий собой значение функции потерь, подлежащей оптимизации.
- Если мы установим это значение как «отклонение», оно будет относиться к отклонению для классификации с вероятностными выходными данными.
- Если мы возведем это значение в «экспоненциальное», то алгоритм AdaBoost восстановится.
Методы кластеризации
Методы кластеризации используются для поиска сходств и закономерностей взаимоотношений между образцами данных и кластеризации их в группы, имеющие сходства на основе признаков. Следующие методы кластеризации доступны в библиотеке Scikit-learn sklearn.cluster.
SНет | Алгоритм | Параметры | Масштабируемость | Используемая метрика |
1 | K-средние | Количество кластеров | Очень большое n_samples | Расстояние между точками. |
2 | Распространение сродства | Демпфирование | Не масштабируется с n_samples | Расстояние графика |
3 | Средний сдвиг | Пропускная способность | Масштабирование с помощью n_samples невозможно. | Расстояние между точками. |
4 | Спектральная кластеризация | Количество кластеров | Средний уровень масштабируемости с n_samples. Низкий уровень масштабируемости с n_clusters. | Расстояние графика |
5 | Иерархическая кластеризация | Порог расстояния или количество кластеров | Большие n_samples Большие n_clusters | Расстояние между точками. |
6 | ДБСКАН | Размер района | Очень большое n_samples и среднее n_clusters. | Расстояние до ближайшей точки |
7 | ОПТИКА | Минимальное членство в кластере | Очень большие n_samples и большие n_clusters. | Расстояние между точками. |
8 | БЕРЕЗА | Порог, фактор ветвления | Большие n_samples Большие n_clusters | Евклидово расстояние между точками. |
Изучите более дюжины инструментов и навыков науки о данных с программой PG по науке о данных и получите доступ к мастер-классам преподавателей Purdue. Зарегистрируйтесь сейчас и добавьте яркую звезду в свое резюме по науке о данных!
Хотите узнать больше?
Scikit-Learn — очень простой инструмент, который позволяет вам узнать, как все работает за кулисами. Как только вы освоите этот инструмент, вы сможете перейти к другим продвинутым инструментам, которые значительно упростят построение моделей. Если вы хотите узнать больше, вы можете ознакомиться с курсом Simplilearn Data Scientist, созданным совместно с IBM. Он включает эксклюзивные хакатоны IBM, мастер-классы, сессии «спроси меня о чем угодно» и живое взаимодействие с практиками, практические лабораторные работы и проекты. Начните этот курс сегодня и улучшите свою карьеру в области науки о данных.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)



