Регрессия против классификации в машинном обучении для начинающих
Наши машины становятся все более интеллектуальными и способными выполнять независимые задачи, и они обязаны этим быстро развивающимся областям искусственного интеллекта и машинного обучения. Однако обе области невероятно сложны и требуют времени и усилий, чтобы лучше их понять.
В этой статье рассматриваются регрессия и классификация в машинном обучении, включая определения, типы, различия и варианты использования.
Ведущий лидер в сфере ИТ, ИБМ определяет машинное обучение как «… отрасль искусственного интеллекта (ИИ) и информатики, которая фокусируется на использовании данных и алгоритмов для имитации того, как люди учатся, постепенно повышая его точность».
Алгоритмы регрессии и классификации известны как алгоритмы контролируемого обучения и используются для прогнозирования в машинном обучении и работы с помеченными наборами данных. Однако их разный подход к проблемам машинного обучения является их точкой расхождения.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)
Теперь давайте более подробно рассмотрим регрессию и классификацию.
Объяснение регрессии в машинном обучении
Регрессия находит корреляции между зависимыми и независимыми переменными. Таким образом, алгоритмы регрессии помогают прогнозировать непрерывные переменные, такие как цены на жилье, рыночные тенденции, погодные условия, цены на нефть и газ (важная задача в наши дни!) и т. д.
Задача алгоритма регрессии — найти функцию отображения, чтобы мы могли сопоставить входную переменную «x» с непрерывной выходной переменной «y».
Объяснение классификации в машинном обучении
С другой стороны, классификация — это алгоритм, который находит функции, которые помогают разделить набор данных на классы на основе различных параметров. При использовании алгоритма классификации компьютерная программа обучается на наборе обучающих данных и классифицирует данные по различным категориям в зависимости от того, что она узнала.
Алгоритмы классификации находят функцию отображения для сопоставления входа «x» с дискретным выходом «y». Алгоритмы оценивают дискретные значения (другими словами, двоичные значения, такие как 0 и 1, да и нет, истина или ложь, на основе определенного набора независимых переменных. Другими словами, алгоритмы классификации прогнозируют возникновение события. вероятность путем подгонки данных к логит-функции.
Алгоритмы классификации используются для классификации электронной почты и спама, прогнозирования готовности клиентов банков платить по кредитам и выявления раковых опухолевых клеток.
Типы регрессии
Вот типы алгоритмов регрессии, которые обычно встречаются в области машинного обучения:
Регрессия дерева решений. Основная цель этой регрессии — разделить набор данных на более мелкие подмножества. Эти подмножества создаются для отображения значения любой точки данных, связанной с постановкой задачи.
- Регрессия главных компонентов. Этот метод регрессии широко используется. Существует много независимых переменных, или в ваших данных существует мультиколлинеарность.
- Полиномиальная регрессия: этот тип соответствует нелинейному уравнению, используя полиномиальные функции независимой переменной.
- Регрессия случайного леса. Регрессия случайного леса широко используется в машинном обучении. Он использует несколько деревьев решений для прогнозирования результата. Случайные точки данных выбираются из заданного набора данных и используются для построения дерева решений с помощью этого алгоритма.
- Простая линейная регрессия: этот тип является наименее сложной формой регрессии, где зависимая переменная является непрерывной.
- Регрессия опорных векторов. Этот тип регрессии решает как линейные, так и нелинейные модели. Он использует нелинейные функции ядра, такие как полиномы, для поиска оптимального решения для нелинейных моделей.
Виды классификации
А вот типы алгоритмов классификации, обычно используемые в машинном обучении:
- Классификация дерева решений. Этот тип делит набор данных на сегменты на основе определенных переменных объектов. Пороговые значения делений обычно представляют собой среднее значение или моду рассматриваемой переменной признака, если они являются числовыми.
K-ближайшие соседи: этот тип классификации определяет K ближайших соседей к данной точке наблюдения. Затем он использует K-баллы для оценки пропорций каждого типа целевой переменной и прогнозирует целевую переменную, которая имеет наибольшее соотношение.
Логистическая регрессия: этот тип классификации несложный, поэтому его можно легко применить при минимальном обучении. Он предсказывает вероятность того, что Y будет связан с входной переменной X.
- Наивный байесовский алгоритм: этот классификатор является одним из наиболее эффективных и простых алгоритмов. Он основан на теореме Байеса, которая описывает, как вероятность события оценивается на основе предыдущих знаний об условиях, которые могут быть связаны с событием.
- Классификация случайного леса. Случайный лес обрабатывает множество деревьев решений, каждое из которых прогнозирует значение вероятности целевой переменной. Затем вы получаете окончательный результат, усредняя вероятности.
- Машины опорных векторов. Этот алгоритм использует классификаторы опорных векторов с интересными изменениями, что делает его идеальным для оценки нелинейных границ решений. Этот процесс возможен за счет увеличения пространства переменных функций за счет использования специальных функций, известных как ядра.
Разница между регрессией и классификацией
Это изображение, любезно предоставленное Javatpoint, иллюстрирует алгоритмы классификации и регрессии.
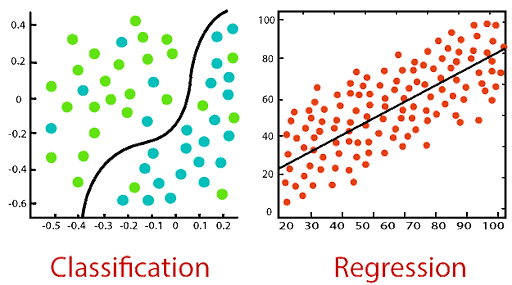
В этой таблице показаны конкретные различия между алгоритмами регрессии и классификации.
Алгоритмы регрессии | Алгоритмы классификации |
Выходная переменная должна иметь либо непрерывную природу, либо действительное значение. | Выходная переменная должна быть дискретным значением. |
Задача алгоритма регрессии — сопоставить входное значение (x) с непрерывной выходной переменной (y). | Задача алгоритма классификации сопоставляет входное значение x с дискретной выходной переменной y. |
Они используются с непрерывными данными. | Они используются с дискретными данными. |
Он пытается найти наиболее подходящую линию, которая более точно предсказывает результат. | Классификация пытается найти границу решения, которая делит набор данных на разные классы. |
Алгоритмы регрессии решают проблемы регрессии, такие как прогнозирование цен на жилье и прогноз погоды. | Алгоритмы классификации решают проблемы классификации, такие как выявление спама по электронной почте, обнаружение раковых клеток и распознавание речи. |
Далее мы можем разделить алгоритмы регрессии на линейную и нелинейную регрессию. | Далее мы можем разделить алгоритмы классификации на бинарные классификаторы и многоклассовые классификаторы. |
Теперь, когда у нас есть четкое представление о различиях между алгоритмами классификации и регрессии, пришло время посмотреть, как они связаны с деревьями решений. Но прежде чем мы это сделаем, нам нужно задать важный вопрос.
Что такое алгоритм дерева решений?
Алгоритмы машинного обучения можно разделить на два типа: контролируемые и неконтролируемые. Деревья принятия решений представляют собой контролируемый алгоритм машинного обучения. Например, деревья принятия решений представляют собой контролируемый алгоритм машинного обучения.
Алгоритмы дерева решений — это операторы if-else, используемые для прогнозирования результата на основе доступных данных.
Вот пример дерева решений, любезно предоставленный Хакереарт. Мы можем использовать это дерево решений, чтобы предсказать сегодняшнюю погоду и посмотреть, стоит ли устроить пикник.
Теперь, когда у нас есть четкое определение базового дерева решений, мы готовы углубиться в деревья классификации и регрессии.
В чем разница между деревом классификации и деревом регрессии?
Деревья классификации и регрессии, известные под общим названием CART, описывают алгоритмы дерева решений, используемые в задачах обучения классификации и регрессии. Лео Брейман, Джером Фридман, Ричард Олшен и Чарльз Стоун представили методологию дерева классификации и регрессии в 1984 году.
Дерево классификации — это алгоритм с фиксированной или категориальной целевой переменной. Затем мы можем использовать алгоритм для определения наиболее вероятного «класса», в который, вероятно, попадет целевая переменная. Эти алгоритмы используются для ответа на вопросы или решения таких проблем, как «Кто, скорее всего, подпишется на эту акцию?» или «Кто пройдет или не пройдет этот курс?»
Оба эти вопроса представляют собой простые двоичные классификации. Категориальная зависимая переменная принимает только одно из двух возможных взаимоисключающих значений. Однако могут возникнуть случаи, когда вам понадобится прогноз, учитывающий несколько переменных, например: «На какую из этих четырех рекламных акций люди, скорее всего, подпишутся?» В этом случае категориальная зависимая переменная имеет несколько значений.
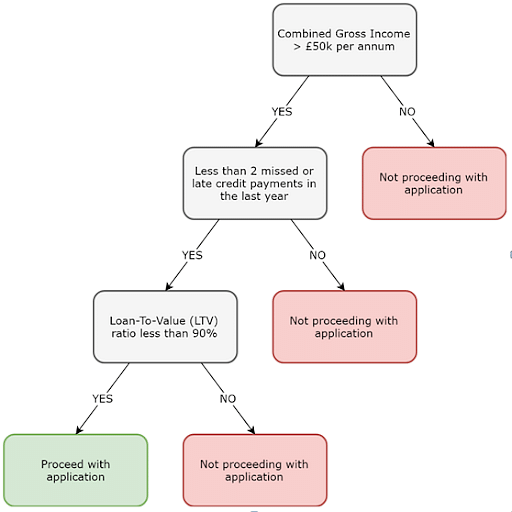
Вот пример дерева классификации, которое будет использовать ипотечный кредитор, любезно предоставлен Datasciencecentral.
Дерево регрессии описывает алгоритм, который принимает упорядоченные значения с непрерывными значениями и прогнозирует значение. Например, вы можете спрогнозировать цену продажи кондоминиума — непрерывную зависимую переменную.
Цена продажи будет зависеть от непрерывных факторов, таких как площадь в квадратных футах, и таких категориальных факторов, как стиль квартиры, расположение объекта и тому подобных факторов.
Вот пример дерева регрессии, любезно предоставленный Рубб. Это дерево рассчитывает зарплаты бейсболистов.
Что касается реальных различий, деревья классификации используются для решения проблем, связанных с результатами классификации, а деревья регрессии работают с проблемами типа прогнозирования. Но давайте посмотрим поближе на различия.
Функциональность
Деревья классификации разделяют набор данных на основе однородности, например пары переменных. Например, мы могли бы использовать две переменные, такие как возраст и пол. Если данные обучения показывают, что 85 процентам мужчин понравился конкретный фильм, в этот момент данные разделяются, и пол становится верхним узлом в дереве. Такое разделение обеспечивает чистоту информации на 85%.
Деревья регрессии соответствуют целевой переменной с использованием всех независимых переменных. Данные каждой независимой переменной затем разделяются в нескольких точках. Ошибка между прогнозируемыми и фактическими значениями возводится в квадрат в каждой точке, чтобы получить сумму квадратов ошибок или SSE. Этот SSE сравнивается по всем переменным, и точка или переменная с наименьшим SSE становится точкой разделения, и процесс продолжается рекурсивно.
Регрессия против классификации: преимущества перед стандартными деревьями решений
Деревья решений классификации и регрессии генерируют точные прогнозы, используя условия if-else. Их преимущества включают в себя:
- Простые результаты. Эти результаты легко наблюдать и классифицировать, что упрощает их оценку и объяснение другим людям.
- Они нелинейны и непараметричны: поскольку оба дерева имеют дело с упрощенными результатами, они избегают неявных предположений, что делает их хорошо подходящими для функций интеллектуального анализа данных.
- Деревья неявно выполняют выбор признаков: отбор переменных, также называемый выбором признаков, жизненно важен для аналитики. Несколько верхних узлов дерева решений являются наиболее важными, поэтому эти деревья решений автоматически обрабатывают выбор функций.
Недостатки деревьев классификации и регрессии
Ни одна система не идеальна. Деревья решений классификации и регрессии приносят свои собственные проблемы и ограничения.
- Они склонны к переоснащению: переобучение происходит, когда дерево учитывает шум, обнаруженный в большинстве данных, и приводит к неточностям.
- Они склонны к высокой дисперсии: даже небольшое отклонение в данных может привести к высокой дисперсии полученного прогноза, создавая нестабильный результат.
- Обычно они имеют низкую систематическую ошибку: сложные деревья решений имеют характерную низкую систематическую ошибку, что затрудняет добавление новых данных.
Когда использовать регрессию или классификацию
Мы используем деревья классификации, когда набор данных необходимо разделить на классы, принадлежащие переменной ответа. В большинстве случаев эти классы — «Да» или «Нет». Таким образом, существует всего два класса, и они являются взаимоисключающими. Конечно, иногда классов может быть больше двух, но в таких случаях мы просто используем вариант алгоритма дерева классификации.
Однако мы используем деревья регрессии, когда у нас есть переменные непрерывного отклика. Например, если переменная ответа представляет собой что-то вроде значения объекта или сегодняшней температуры, мы используем дерево регрессии.
Дерево решений — это регрессия или модель классификации?
Легко определить, какая модель какая. Короче говоря, модель дерева решений регрессии используется для прогнозирования непрерывных значений, тогда как модель дерева решений классификации имеет дело с двоичной ситуацией «или-или».
Выберите правильную программу
Улучшите свою карьеру в области искусственного интеллекта и машинного обучения с помощью комплексных курсов Simplilearn. Получите навыки и знания, которые помогут преобразовать отрасли и раскрыть свой истинный потенциал. Зарегистрируйтесь сейчас и откройте безграничные возможности!
Название программы | Инженер по искусственному интеллекту | Последипломная программа в области искусственного интеллекта | Последипломная программа в области искусственного интеллекта |
| Гео | Все регионы | Все регионы | В/СТРОКА |
| Университет | Простое обучение | Пердью | Калтех |
| Длительность курса | 11 месяцев | 11 месяцев | 11 месяцев |
| Требуется опыт кодирования | Базовый | Базовый | Нет |
| Навыки, которые вы изучите | Более 10 навыков, включая структуру данных, манипулирование данными, NumPy, Scikit-Learn, Tableau и многое другое. | 16+ навыков, включая чат-боты, НЛП, Python, Keras и многое другое. | 8+ навыков, включая Контролируемое и неконтролируемое обучение Глубокое обучение Визуализация данных и многое другое. |
| Дополнительные преимущества | Получите доступ к эксклюзивным хакатонам, мастер-классам и сеансам «Спроси меня о чем-нибудь» от IBM Прикладное обучение посредством 3 основных и 12 отраслевых проектов. | Членство в Ассоциации выпускников Purdue Бесплатное членство в IIMJobs на 6 месяцев Помощь в составлении резюме | До 14 кредитов CEU Членство в кружке Caltech CTME |
| Расходы | $$ | $$$$ | $$$$ |
| Изучите программу | Изучите программу | Изучите программу |
Хотите стать профессионалом в области машинного обучения?
Если вы ищете карьеру, которая сочетает в себе вызов, гарантию занятости и отличную оплату труда, не ищите ничего, кроме захватывающей и быстро развивающейся области машинного обучения. Мы видим, как с каждым днем все больше роботов, беспилотных автомобилей и интеллектуальных прикладных ботов выполняют все более сложные задачи.
Simplilearn может помочь вам освоить эту фантастическую область благодаря курсу искусственного интеллекта и машинного обучения. Эта программа включает 58 часов прикладного обучения, интерактивные лаборатории, четыре практических проекта и наставничество. Вы получите углубленный взгляд на темы машинного обучения, такие как работа с данными в реальном времени, разработка алгоритмов контролируемого и неконтролируемого обучения, регрессия, классификация и моделирование временных рядов. Кроме того, вы узнаете, как использовать Python для составления прогнозов на основе данных.
Simplilearn также предлагает другие курсы, связанные с искусственным интеллектом и машинным обучением, такие как курс искусственного интеллекта Калифорнийского технологического института.
В соответствии с Стеклянная дверь, Инженеры по машинному обучению в США могут зарабатывать в среднем 123 764 доллара в год, а в Индияаналогичная позиция предлагает в среднем 1 000 000 фунтов стерлингов в год!
Позвольте Simplilearn помочь вам занять свое место в этом удивительном новом мире машинного обучения и предоставить вам инструменты для создания лучшего будущего для вашей карьеры. Итак, посетите Simplilearn сегодня и сделайте первые жизненно важные шаги!
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)




