Алгоритм кластеризации K-средних: приложения, типы и демонстрации (обновлено)
Каждый инженер машинного обучения хочет добиться точных прогнозов с помощью своих алгоритмов. Такие алгоритмы обучения обычно делятся на два типа — контролируемые и неконтролируемые. Кластеризация K-средних — один из неконтролируемых алгоритмов, где доступные входные данные не имеют помеченного ответа.
Типы кластеризации
Кластеризация — это тип неконтролируемого обучения, при котором точки данных группируются в различные наборы на основе степени их сходства.
Различают следующие типы кластеризации:
- Иерархическая кластеризация
- Разделение кластеризации
Иерархическая кластеризация далее подразделяется на:
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)
- Агломеративная кластеризация
- Разделительная кластеризация
Кластеризация с разделением далее подразделяется на:
- Кластеризация K-средних
- Нечеткая кластеризация C-средних
Ваша карьера в области искусственного интеллекта/машинного обучения уже не за горами!Магистерская программа «Инженер искусственного интеллекта»Изучить программу![]()
Иерархическая кластеризация
Иерархическая кластеризация использует древовидную структуру, например:
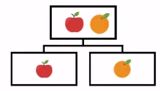
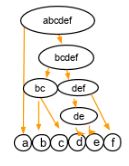
В агломеративной кластеризации используется подход снизу вверх. Мы начинаем с каждого элемента как отдельного кластера и объединяем их в последовательно более массивные кластеры, как показано ниже:
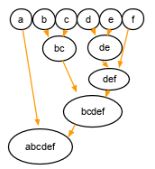
Разделительная кластеризация — это подход сверху вниз. Мы начинаем со всего набора и продолжаем делить его на последовательно меньшие кластеры, как вы можете видеть ниже:
Разделение Кластеризация
Разделительная кластеризация делится на два подтипа — кластеризация K-средних и нечеткая кластеризация C-средних.
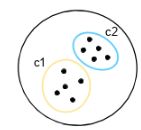
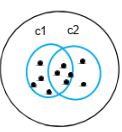
В кластеризации k-средних объекты делятся на несколько кластеров, обозначенных числом «К». Так что если мы скажем, что К = 2, объекты делятся на два кластера, c1 и c2, как показано:
Освойте стратегии Gen AI для бизнеса с программой Generation AI for Business Transformation ProgramИзучите программу![]()
Здесь сравниваются признаки или характеристики, и все объекты, имеющие схожие характеристики, объединяются в одну группу.
Нечеткий c-means очень похож на k-means в том смысле, что он кластеризует объекты, имеющие схожие характеристики. В кластеризации k-means один объект не может принадлежать двум разным кластерам. Но в c-means объекты могут принадлежать более чем к одному кластеру, как показано.
Что подразумевается под алгоритмом кластеризации K-средних?
Кластеризация K-Means — это алгоритм неконтролируемого обучения. Для этой кластеризации нет помеченных данных, в отличие от контролируемого обучения. K-Means выполняет разделение объектов на кластеры, которые имеют сходства и отличаются от объектов, принадлежащих другому кластеру.
Термин «K» — это число. Вам нужно сообщить системе, сколько кластеров вам нужно создать. Например, K = 2 относится к двум кластерам. Существует способ узнать, какое значение K является наилучшим или оптимальным для заданных данных.
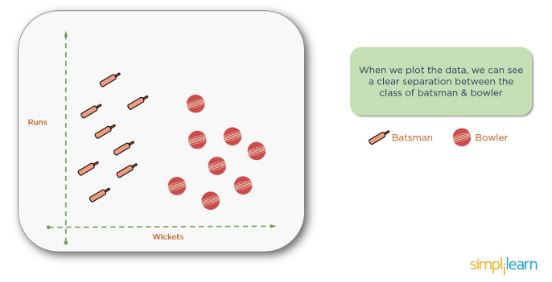
Для лучшего понимания k-средних давайте рассмотрим пример из крикета. Представьте, что вы получили данные о множестве игроков в крикет со всего мира, которые содержат информацию о набранных игроком ранах и взятых им калитках в последних десяти матчах. На основе этой информации нам нужно сгруппировать данные в два кластера, а именно бэтсменов и боулеров.
Давайте рассмотрим шаги по созданию этих кластеров.
Решение:
Назначить точки данных
Здесь у нас есть набор данных, нанесенный на координаты 'x' и 'y'. Информация по оси y касается набранных очков, а по оси x — взятых игроками калиток.
Если мы представим данные в виде графика, то он будет выглядеть следующим образом:
Выполнить кластеризацию
Нам необходимо создать кластеры, как показано ниже:
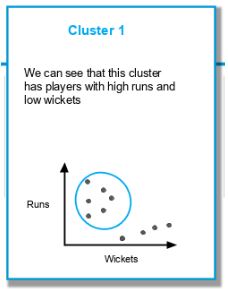
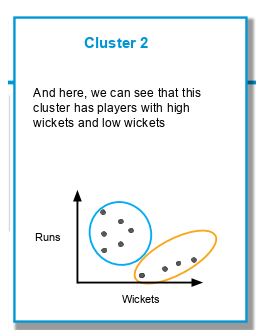
Рассмотрим тот же набор данных и решим задачу, используя кластеризацию K-средних (приняв K = 2).
Первый шаг в кластеризации k-средних — это случайное распределение двух центроидов (так как K=2). Две точки назначаются в качестве центроидов. Обратите внимание, что точки могут находиться где угодно, так как они являются случайными точками. Они называются центроидами, но изначально они не являются центральной точкой заданного набора данных.

Следующий шаг — определить расстояние между каждой из случайно назначенных точек данных центроидов. Для каждой точки расстояние измеряется от обоих центроидов, и если расстояние меньше, то эта точка назначается этому центроиду. Вы можете видеть точки данных, прикрепленные к центроидам и представленные здесь синим и желтым цветом.

Следующий шаг — определить фактический центроид для этих двух кластеров. Исходный случайно выделенный центроид должен быть перемещен в фактический центроид кластеров.

Этот процесс вычисления расстояния и перепозиционирования центроида продолжается до тех пор, пока мы не получим наш окончательный кластер. Затем перепозиционирование центроида прекращается.

Как видно выше, центроид больше не нуждается в изменении положения, а это значит, что алгоритм сошелся, и у нас есть два кластера с центроидом.
Ваша карьера в области искусственного интеллекта/машинного обучения уже не за горами!Магистерская программа «Инженер искусственного интеллекта»Изучить программу![]()
Преимущества метода k-средних
- Простота и удобство реализации: алгоритм k-средних прост в понимании и реализации, что делает его популярным выбором для задач кластеризации.
- Быстрота и эффективность: метод K-средних эффективен с точки зрения вычислений и может обрабатывать большие наборы данных с высокой размерностью.
- Масштабируемость: алгоритм K-средних может обрабатывать большие наборы данных с большим количеством точек данных и может быть легко масштабирован для обработки еще больших наборов данных.
- Гибкость: метод K-средних можно легко адаптировать к различным приложениям и использовать с различными метриками расстояния и методами инициализации.
Недостатки метода K-средних:
- Чувствительность к начальному центроиду: метод K-средних чувствителен к начальному выбору центроидов и может сходиться к неоптимальному решению.
- Необходимо указать количество кластеров: количество кластеров k необходимо указать до запуска алгоритма, что может оказаться сложной задачей в некоторых приложениях.
- Чувствительность к выбросам: метод K-средних чувствителен к выбросам, которые могут оказать существенное влияние на полученные кластеры.
Применение кластеризации методом K-средних
Кластеризация K-средних используется в различных примерах или бизнес-кейсах в реальной жизни, например:
- Академическая успеваемость
- Диагностические системы
- Поисковые системы
- Беспроводные сенсорные сети
Академическая успеваемость
На основании полученных баллов учащиеся распределяются по категориям: A, B или C.
Диагностические системы
Медицина использует метод k-средних для создания более интеллектуальных систем поддержки принятия медицинских решений, особенно при лечении заболеваний печени.
Поисковые системы
Кластеризация формирует основу поисковых систем. Когда выполняется поиск, результаты поиска необходимо сгруппировать, и поисковые системы очень часто используют кластеризацию для этого.
Беспроводные сенсорные сети
Алгоритм кластеризации выполняет функцию поиска головных частей кластера, которые собирают все данные в соответствующем кластере.
Измерение расстояния
Мера расстояния определяет сходство между двумя элементами и влияет на форму кластеров.
Кластеризация K-средних поддерживает различные виды мер расстояния, такие как:
- Евклидова мера расстояния
- Манхэттенская мера расстояния
- Квадрат евклидовой меры расстояния
- Косинусная мера расстояния
Евклидова мера расстояния
Наиболее распространенный случай — определение расстояния между двумя точками. Если у нас есть точка P и точка Q, то евклидово расстояние — это обычная прямая линия. Это расстояние между двумя точками в евклидовом пространстве.
Формула для расстояния между двумя точками показана ниже:
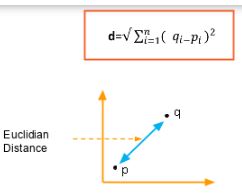
Квадрат евклидовой меры расстояния
Это идентично евклидову измерению расстояния, но не берет квадратный корень в конце. Формула показана ниже:
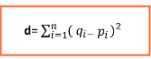
Манхэттенская мера расстояния
Манхэттенское расстояние — это простая сумма горизонтальной и вертикальной составляющих или расстояние между двумя точками, измеренное вдоль осей под прямым углом.
Обратите внимание, что мы берем абсолютное значение, чтобы отрицательные значения не вступали в игру.
Формула показана ниже:
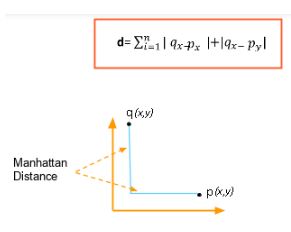
Косинусная мера расстояния
В этом случае мы берем угол между двумя векторами, образованными путем соединения начальной точки. Формула приведена ниже:
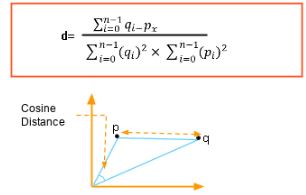
Станьте специалистом по обработке данных с помощью практического обучения!Программа магистратуры для специалистов по обработке данныхИзучить программу![]()
K-средние по сегментации извержений гейзеров
K-means можно использовать для сегментации набора данных Geyser's Eruptions, который регистрирует продолжительность и время ожидания между извержениями гейзера Old Faithful в Йеллоустонском национальном парке. Алгоритм можно использовать для кластеризации извержений на основе их продолжительности и времени ожидания и выявления различных моделей извержений.
K-means при сжатии изображений
K-means также может использоваться для сжатия изображений, где он может быть использован для уменьшения количества цветов в изображении, сохраняя его визуальное качество. Алгоритм может быть использован для кластеризации цветов в изображении и замены пикселей на центроидный цвет каждого кластера, что приводит к сжатию изображения.
Методы оценки
Методы оценки используются для измерения производительности алгоритмов кластеризации. Распространенные методы оценки включают:
Сумма квадратов ошибок (SSE): измеряет сумму квадратов расстояний между каждой точкой данных и назначенным ей центроидом.
Коэффициент силуэта: измеряет сходство точки данных с ее собственным кластером по сравнению с другими кластерами. Высокий коэффициент силуэта указывает на то, что точка данных хорошо соответствует своему собственному кластеру и плохо соответствует соседним кластерам.
Анализ силуэта
Силуэтный анализ — это графический метод оценки качества кластеров, созданных алгоритмом кластеризации. Он включает в себя расчет коэффициента силуэта для каждой точки данных и построение их на гистограмме. Ширина гистограммы указывает на качество кластеризации. Широкая гистограмма указывает на то, что кластеры хорошо разделены и различимы, в то время как узкая гистограмма указывает на то, что кластеры плохо разделены и могут перекрываться.
Как работает кластеризация K-средних?
На приведенной ниже блок-схеме показано, как работает кластеризация методом k-средних:
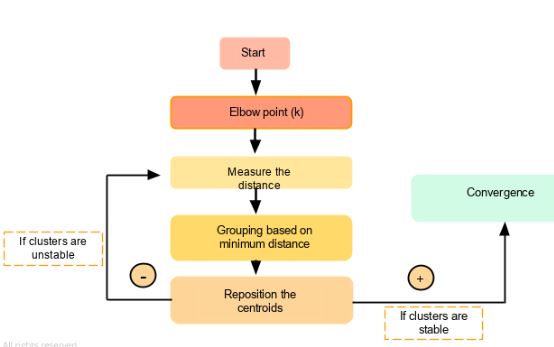
Цель алгоритма K-средних — найти кластеры в заданных входных данных. Есть несколько способов сделать это. Мы можем использовать метод проб и ошибок, указав значение K (например, 3,4, 5). По мере продвижения мы продолжаем изменять значение, пока не получим лучшие кластеры.
Другой метод заключается в использовании техники Elbow для определения значения K. Как только мы получим значение K, система случайным образом назначит столько центроидов и измерит расстояние каждой из точек данных от этих центроидов. Соответственно, она назначает эти точки соответствующему центроиду, расстояние от которого минимально. Таким образом, каждая точка данных будет назначена центроиду, который находится ближе всего к ней. Таким образом, у нас есть K начальных кластеров.
Для вновь образованных кластеров он вычисляет новое положение центроида. Положение центроида перемещается по сравнению со случайно выделенным.
Снова измеряется расстояние каждой точки от этой новой точки центроида. При необходимости точки данных перемещаются в новые центроиды, и среднее положение или новый центроид вычисляется еще раз.
Если центроид движется, итерация продолжается, указывая на отсутствие сходимости. Но как только центроид перестает двигаться (что означает, что процесс кластеризации сошелся), он отразит результат.
Давайте воспользуемся примером визуализации, чтобы лучше это понять.
У нас есть набор данных для продуктового магазина, и мы хотим узнать, на сколько кластеров его нужно распределить. Чтобы найти оптимальное количество кластеров, мы разбиваем его на следующие шаги:
Шаг 1:
Метод Elbow — лучший способ найти количество кластеров. Метод Elbow представляет собой запуск кластеризации K-Means на наборе данных.
Далее мы используем внутрисумму квадратов как меру для нахождения оптимального количества кластеров, которые могут быть сформированы для заданного набора данных. Внутрисумма квадратов (WSS) определяется как сумма квадратов расстояния между каждым членом кластера и его центроидом.

WSS измеряется для каждого значения K. Значение K, которое имеет наименьшее количество WSS, принимается в качестве оптимального значения.
Теперь нарисуем кривую между WSS и количеством кластеров.
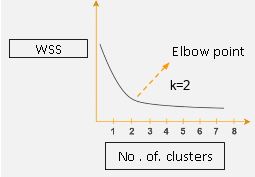
Здесь WSS находится на оси Y, а количество кластеров — на оси X.
Вы можете видеть, что происходит очень постепенное изменение значения WSS по мере увеличения значения K от 2.
Итак, можно взять значение точки локтя как оптимальное значение K. Оно должно быть либо два, либо три, либо максимум четыре. Но, помимо этого, увеличение количества кластеров не приводит к кардинальному изменению значения в WSS, оно стабилизируется.
Ваша карьера в области искусственного интеллекта/машинного обучения уже не за горами!Магистерская программа «Инженер искусственного интеллекта»Изучить программу![]()
Шаг 2:
Предположим, что это наши пункты доставки:
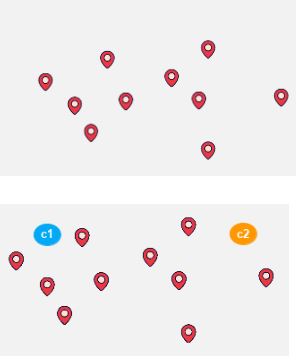
Мы можем случайным образом инициализировать две точки, называемые центроидами кластера.
Здесь C1 и C2 — центроиды, назначенные случайным образом.
Шаг 3:
Теперь измеряется расстояние каждой точки от центроида, и каждая точка данных присваивается центроиду, который находится ближе всего к ней.
Вот как осуществляется первоначальная группировка:
Шаг 4:
Вычислите фактический центроид точек данных для первой группы.
Шаг 5:
Переместите случайный центроид в фактический центроид.
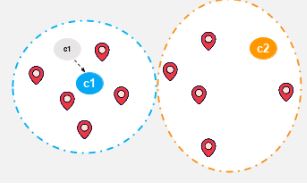
Шаг 6:
Вычислите фактический центроид точек данных для второй группы.
Шаг 7:
Переместите случайный центроид в фактический центроид.
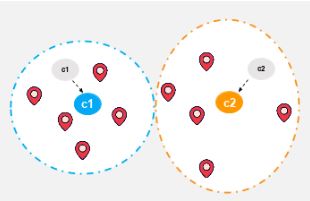
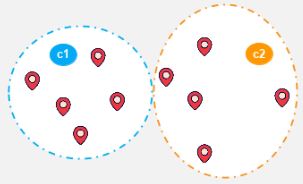
Шаг 8:
Как только кластер становится статичным, говорят, что алгоритм k-средних сошелся.
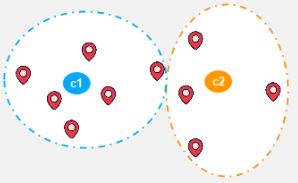
Окончательный кластер с центроидами c1 и c2 показан ниже:
Алгоритм кластеризации K-средних
Допустим, у нас есть входные данные x1, x2, x3… x(n), и мы хотим разделить их на K кластеров.
Шаги по формированию кластеров следующие:
Шаг 1: Выберите K случайных точек в качестве центров кластеров, называемых центроидами.
Шаг 2: Назначить каждый x(i) ближайшему кластеру, используя евклидово расстояние (т.е. вычислив его расстояние до каждого центроида)
Шаг 3: Определите новые центроиды, взяв среднее значение назначенных точек.
Шаг 4: Продолжайте повторять шаги 2 и 3, пока не будет достигнута конвергенция.
Давайте подробно рассмотрим каждый из этих шагов.
Шаг 1:
Мы случайным образом выбираем K (центроиды). Мы называем их c1,c2,….. ck, и мы можем сказать, что
![]()
Где C — множество всех центроидов.
Ваша карьера в области искусственного интеллекта/машинного обучения уже не за горами!Магистерская программа «Инженер искусственного интеллекта»Изучить программу![]()
Шаг 2:
Мы сопоставляем каждую точку данных с ее ближайшим центром, что достигается путем вычисления евклидова расстояния.
![]()
Где dist() — евклидово расстояние.
Здесь мы вычисляем расстояние каждого значения x от каждого значения c, т. е. расстояние между x1-c1, x1-c2, x1-c3 и т. д. Затем мы находим, какое значение является наименьшим, и присваиваем x1 этому конкретному центроиду.
Аналогично находим минимальное расстояние для x2, x3 и т.д.
Шаг 3:
Фактический центроид определяется путем усреднения всех точек, отнесенных к этому кластеру.
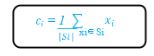
Где Si — множество всех точек, отнесенных к i-му кластеру.
Это означает, что исходная точка, которую мы считали центроидом, сместится в новое положение, которое является фактическим центроидом для каждой из этих групп.
Шаг 4:
Продолжайте повторять шаги 2 и 3, пока не будет достигнута конвергенция.
Как выбрать значение «числа кластеров K» в кластеризации K-средних?
Хотя существует множество вариантов выбора оптимального количества кластеров, метод локтя является одним из самых популярных и подходящих методов. Метод локтя использует идею значения WCSS, что является сокращением от Within Cluster Sum of Squares (сумма квадратов внутри кластера). WCSS определяет общее количество вариаций внутри кластера. Это формула, используемая для расчета значения WCSS (для трех кластеров), предоставленная любезно Java-точка:
WCSS= ∑Pi в Кластере1 расстояние(Pi C1)2 +∑Pi в Кластере2 расстояние(Pi C2)2+∑Pi в Кластере3 расстояние(Pi C3)2
Реализация алгоритма кластеризации K-средних на языке Python
Вот как использовать Python для реализации алгоритма кластеризации K-средних. Вот шаги, которые вам нужно предпринять:
- Предварительная обработка данных
- Нахождение оптимального количества кластеров методом локтя
- Обучение алгоритма K-Means на обучающем наборе данных
- Визуализация кластеров
1. Предварительная обработка данных. Импортируйте библиотеки, наборы данных и извлеките независимые переменные.
# импорт библиотек
импортировать numpy как nm
импортировать matplotlib.pyplot как mtp
импортировать панды как pd
# Импорт набора данных
набор данных = pd.read_csv('Mall_Customers_data.csv')
x = dataset.iloc(:, (3, 4)).values
2. Найдите оптимальное количество кластеров с помощью метода локтя. Вот код, который вы используете:
#поиск оптимального количества кластеров с использованием метода локтя
из sklearn.cluster импорт KMeans
wcss_list= () #Инициализация списка значений WCSS
#Использование цикла for для итераций от 1 до 10.
для i в диапазоне (1, 11):
kmeans = KMeans(n_clusters=i, init='k-means++', random_state= 42)
kmeans.fit(x)
wcss_list.append(kmeans.inertia_)
mtp.plot(диапазон(1, 11), wcss_list)
mtp.title('Граф метода Elobw')
mtp.xlabel('Количество кластеров(k)')
mtp.ylabel('wcss_list')
mtp.показать()
3. Обучите алгоритм K-средних на обучающем наборе данных. Используйте те же две строки кода, что и в предыдущем разделе. Однако вместо i используйте 5, поскольку необходимо сформировать 5 кластеров. Вот код:
#обучение модели K-средних на наборе данных
kmeans = KMeans(n_clusters=5, init='k-means++', random_state= 42)
y_predict= kmeans.fit_predict(x)
4. Визуализируйте кластеры. Поскольку эта модель имеет пять кластеров, нам нужно визуализировать каждый из них.
#визуализация кластеров
mtp.scatter(x(y_predict == 0, 0), x(y_predict == 0, 1), s = 100, c = 'blue', label = 'Cluster 1') #для первого кластера
mtp.scatter(x(y_predict == 1, 0), x(y_predict == 1, 1), s = 100, c = 'зеленый', label = 'Кластер 2') #для второго кластера
mtp.scatter(x(y_predict== 2, 0), x(y_predict == 2, 1), s = 100, c = 'red', label = 'Cluster 3') #для третьего кластера
mtp.scatter(x(y_predict == 3, 0), x(y_predict == 3, 1), s = 100, c = 'cyan', label = 'Cluster 4') #для четвертого кластера
mtp.scatter(x(y_predict == 4, 0), x(y_predict == 4, 1), s = 100, c = 'magenta', label = 'Cluster 5') #для пятого кластера
mtp.scatter(kmeans.cluster_centers_(:, 0), kmeans.cluster_centers_(:, 1), s = 300, c = 'желтый', label = 'Центроид')
mtp.title('Кластеры клиентов')
mtp.xlabel('Годовой доход (тыс. $)')
mtp.ylabel('Оценка расходов (1-100)')
mtp.легенда()
mtp.показать()
Кодирование предоставлено Джаватпойнт.
Демонстрация: Кластеризация K-средних
Постановка задачи. Walmart хочет открыть сеть магазинов по всему штату Флорида и найти оптимальные места расположения магазинов, чтобы максимизировать доход.
Проблема здесь в том, что если они откроют слишком много магазинов близко друг к другу, они не получат прибыли. Но если магазины находятся слишком далеко друг от друга, у них не будет достаточного охвата продаж.
Решение – Организация вроде Walmart является гигантом электронной коммерции. У них уже есть адреса клиентов в базе данных. Поэтому они могут использовать эту информацию и выполнить кластеризацию K-средних, чтобы найти оптимальное местоположение.
Заключение
Инженеры машинного обучения, считающиеся профессией будущего, востребованы и высокооплачиваемы. Отчет Обзор рынка прогнозирует темпы роста машинного обучения более чем на 45% в период с 2017 по 2025 год. Так зачем же ограничивать свое обучение только алгоритмами кластеризации K-средних? Запишитесь на курс машинного обучения Simplilearn и расширьте свои знания в более широких концепциях машинного обучения. Получите сертификат и станьте частью талантов в области искусственного интеллекта, которых компании постоянно ждут.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)




