Алгоритм A* в области искусственного интеллекта, который вы должны знать в 2024 году
Проверено и проверено Саянтони Дасом
Алгоритмы поиска — это алгоритмы, предназначенные для поиска или извлечения элементов из структуры данных, где они хранятся. Они необходимы для доступа к нужным элементам структуры данных и их извлечения при возникновении необходимости. Важным аспектом алгоритмов поиска является поиск пути, который используется для поиска путей, по которым можно пройти из одной точки в другую, путем нахождения наиболее оптимального маршрута.
В этом уроке под названием «Алгоритм A* — введение в мощный алгоритм поиска» вы будете иметь дело с алгоритмом A*, который представляет собой алгоритм поиска, который находит кратчайший путь между двумя точками.
Ваша карьера в области искусственного интеллекта и машинного обучения уже не за горами! Магистерская программа AI EngineerИзучите программу![]()
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)
Что такое алгоритм A*?
Это алгоритм поиска, который используется для поиска кратчайшего пути между начальной и конечной точкой.
Это удобный алгоритм, который часто используется для обхода карты, чтобы найти кратчайший путь. Первоначально A* была разработана как задача обхода графа, чтобы помочь построить робота, который может найти свой собственный курс. Он до сих пор остается широко популярным алгоритмом обхода графа.
Сначала он ищет более короткие пути, что делает его оптимальным и полным алгоритмом. Оптимальный алгоритм найдет решение проблемы с наименьшей стоимостью, тогда как полный алгоритм находит все возможные результаты проблемы.
Еще один аспект, который делает A* таким мощным, — это использование взвешенных графов в его реализации. Взвешенный график использует числа для представления стоимости каждого пути или курса действий. Это означает, что алгоритмы могут выбрать путь с наименьшими затратами и найти лучший маршрут с точки зрения расстояния и времени.
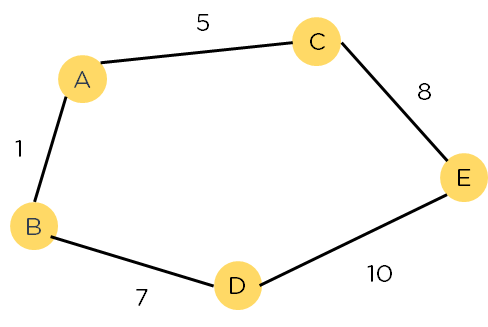
Рисунок 1: Взвешенный график
Основным недостатком алгоритма является его пространственная и временная сложность. Для хранения всех возможных путей требуется большое количество места и много времени для их поиска.
(Связанное чтение: 45 лучших вопросов и ответов на собеседовании по структуре данных на 2022 год)
Приложения алгоритма A*
Алгоритм A* широко используется в различных областях для решения задач поиска пути и оптимизации. Он находит применение в робототехнике, видеоиграх, планировании маршрутов, логистике и искусственном интеллекте. В робототехнике A* помогает роботам преодолевать препятствия и находить оптимальные пути. В видеоиграх это позволяет NPC разумно перемещаться по игровой среде. Приложения для планирования маршрутов используют A* для поиска кратчайших или быстрых маршрутов между точками. Логистические отрасли используют A* для маршрутизации и планирования транспортных средств. A* также используется в системах искусственного интеллекта, таких как обработка естественного языка и машинное обучение, для оптимизации процессов принятия решений. Его универсальность и эффективность делают его ценным алгоритмом во многих реальных сценариях.
Почему алгоритм поиска A*?
Алгоритм поиска A* — это простой и эффективный алгоритм поиска, который можно использовать для поиска оптимального пути между двумя узлами графа. Он будет использоваться для поиска кратчайшего пути. Это расширение алгоритма Дейкстры кратчайшего пути (алгоритм Дейкстры). Расширение здесь заключается в том, что вместо использования приоритетной очереди для хранения всех элементов мы используем для их хранения кучи (двоичные деревья). Алгоритм поиска A* также использует эвристическую функцию, которая предоставляет дополнительную информацию о том, насколько далеко мы находимся от целевого узла. Эта функция используется вместе со структурой данных f-кучи, чтобы сделать поиск более эффективным.
Давайте теперь посмотрим на краткое объяснение алгоритма A*.
Объяснение
Если у нас есть сетка со множеством препятствий и мы хотим добраться куда-то как можно быстрее, алгоритмы поиска A* станут нашим спасением. Из заданной начальной ячейки мы можем максимально быстро добраться до целевой ячейки. Это сумма значений двух переменных, которая определяет узел, который он выбирает в любой момент времени.
На каждом этапе он выбирает узел с наименьшим значением «f» (сумма «g» и «h») и обрабатывает этот узел/ячейку. 'g' и 'h' определены максимально просто ниже:
- 'g' — это расстояние, необходимое, чтобы добраться до определенного квадрата сетки от начальной точки, следуя по пути, который мы создали, чтобы добраться туда.
- «h» — это эвристика, которая представляет собой оценку расстояния, которое необходимо, чтобы добраться до финиша от этого квадрата сетки.
Эвристика – это, по сути, обоснованные предположения. Крайне важно понимать, что мы не знаем расстояния до финишной точки, пока не найдем маршрут, поскольку на пути может возникнуть множество вещей (например, стены, вода и т. д.). В следующих разделах мы углубимся в то, как вычислять эвристики.
Давайте теперь посмотрим на подробный алгоритм A*.
Ваша карьера в области искусственного интеллекта и машинного обучения уже не за горами! Магистерская программа AI EngineerИзучите программу![]()
Алгоритм
Исходное условие — создаём два списка — Открытый список и Закрытый список.
Теперь необходимо реализовать следующие шаги:
- Открытый список должен быть инициализирован.
- Поместите начальный узел в открытый список (оставьте его f равным нулю). Инициализируйте закрытый список.
- Следуйте инструкциям, пока открытый список не станет пустым:
- Найдите в открытом списке узел с наименьшим f и назовите его «q».
- Удалить Q из открытого списка.
- Создайте восемь потомков q и установите q в качестве их родителя.
- Для каждого потомка:
i) Если целью является поиск преемника, прекратите поиски
ii) В противном случае вычислите g и h для преемника.
преемник.g = qg + рассчитанное расстояние между преемником и q.
преемник.h = рассчитанное расстояние между преемником и целью. Для этого мы рассмотрим три эвристики: диагональную, евклидову и манхэттенскую эвристику.
преемник.f = преемник.g плюс преемник.h
iii) Пропустить этого преемника, если в списке OPEN присутствует узел с тем же местоположением, что и он, но с меньшим значением f, чем у преемника.
iv) Пропустить преемника, если в ЗАКРЫТОМ списке есть узел с той же позицией, что и преемник, но с меньшим значением f; в противном случае добавьте узел в конец открытого списка (цикл for).
- Нажмите Q в закрытый список и завершите цикл while.
Теперь мы обсудим, как рассчитать эвристику для узлов.
Мастер-инструменты, необходимые для того, чтобы стать инженером по искусственному интеллектуМагистерская программа для инженеров по искусственному интеллектуИзучите программу![]()
Эвристика
Мы можем легко вычислить g, но как на самом деле вычислить h?
Есть два метода, которые мы можем использовать для расчета значения h:
1. Определить точное значение h (что, безусловно, отнимает много времени).
(или)
2. Используйте различные методы для аппроксимации значения h. (меньше времени).
Давайте обсудим оба метода.
Точная эвристика
Хотя мы можем получить точные значения h, обычно это занимает очень много времени.
Способы определения точного значения h перечислены ниже.
1. Прежде чем использовать алгоритм поиска A*, предварительно рассчитайте расстояние между каждой парой ячеек.
2. Используя формулу расстояния/евклидово расстояние, мы можем напрямую определить точное значение h при отсутствии заблокированных ячеек или препятствий.
Давайте посмотрим, как рассчитать эвристику аппроксимации.
Подготовьте свою карьеру в области искусственного интеллекта и машинного обучения на будущее: что можно и чего нельзя делатьБесплатный вебинар | 5 дек, вторник | 19:00 ISTЗарегистрируйтесь сейчас![]()
Аппроксимационная эвристика
Для определения h обычно используются три эвристики аппроксимации:
1. Манхэттенское расстояние
Манхэттенское расстояние представляет собой сумму абсолютных значений расхождений между координатами x и y текущей и целевой ячеек.
Формула кратко изложена ниже:
h = абс (curr_cell.x – цель.x) +
абс (curr_cell.y – цель.y)
Мы должны использовать этот эвристический метод, когда нам разрешено двигаться только в четырех направлениях — вверх, влево, вправо и вниз.
Давайте теперь посмотрим на метод диагонального расстояния для расчета эвристики.
2. Диагональное расстояние
Это не что иное, как наибольшее абсолютное значение разницы между координатами x и y текущей ячейки и целевой ячейки.
Это суммировано ниже в следующей формуле:
dx = abs(curr_cell.x – цель.x)
dy = abs(curr_cell.y – цель.y)
h = D * (dx + dy) + (D2 – 2 * D) * min(dx, dy)
где D — длина каждого узла (по умолчанию = 1), а D2 — диагональ.
Мы используем этот эвристический метод, когда нам разрешено двигаться только в восьми направлениях, как ходы короля в шахматах.
Давайте теперь взглянем на метод Евклидова расстояния для расчета эвристики.
3. Евклидово расстояние
Евклидово расстояние — это расстояние между целевой ячейкой и текущей ячейкой с использованием формулы расстояния:
h = sqrt ( (curr_cell.x – цель.x)^2 +
(curr_cell.y – цель.y)^2 )
Мы используем этот эвристический метод, когда нам разрешено двигаться в любом направлении по нашему выбору.
Хотите стать инженером по искусственному интеллекту? Не ищите дальше! Магистерская программа AI EngineerИзучите программу![]()
Основная концепция алгоритма A*
Эвристический алгоритм жертвует оптимальностью и точностью ради скорости, чтобы решать проблемы быстрее и эффективнее.
Все графы имеют разные узлы или точки, которые алгоритм должен пройти, чтобы достичь конечного узла. Все пути между этими узлами имеют числовое значение, которое считается весом пути. Сумма всех поперечных путей дает вам стоимость этого маршрута.
Первоначально алгоритм вычисляет стоимость для всех своих непосредственных соседних узлов n и выбирает тот, который несет наименьшую стоимость. Этот процесс повторяется до тех пор, пока не будут выбраны новые узлы и не будут пройдены все пути. Затем вам следует рассмотреть лучший путь среди них. Если f(n) представляет окончательную стоимость, то ее можно обозначить как:
f(n) = g(n) + h(n), где:
g(n) = стоимость перехода от одного узла к другому. Это будет варьироваться от узла к узлу
h(n) = эвристическая аппроксимация значения узла. Это не реальная стоимость, а приблизительная стоимость.
Ваша карьера в области искусственного интеллекта и машинного обучения уже не за горами! Магистерская программа AI EngineerИзучите программу![]()
Как работает алгоритм A*?
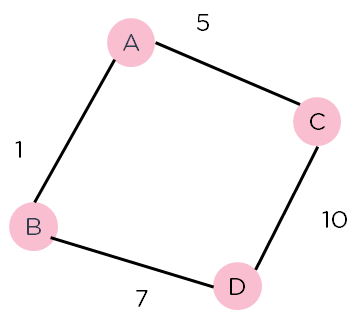
Рисунок 2. Взвешенный график 2.
Рассмотрим взвешенный граф, изображенный выше, который содержит узлы и расстояния между ними. Допустим, вы начинаете с А и вам нужно идти в D.
Теперь, поскольку начало находится в источнике A, который будет иметь некоторую начальную эвристическую ценность. Следовательно, результаты
е(А) = г(А) + ч(А)
е(А) = 0 + 6 = 6
Далее пройдем путь к другим соседним вершинам:
е(АВ) = 1 + 4
е(АС) = 5 + 2
Теперь проложите путь к месту назначения от этих узлов и рассчитайте веса:
f(ABD) = (1+ 7) + 0
f(ACD) = (5 + 10) + 0
Понятно, что узел B дает вам лучший путь, поэтому именно этот узел вам нужно пройти, чтобы добраться до пункта назначения.
Псевдокод алгоритма A*
Текст ниже представляет собой псевдокод алгоритма. Его можно использовать для реализации алгоритма на любом языке программирования, и он является базовой логикой алгоритма.
- Создайте открытый список, содержащий начальный узел
- Если он достигает узла назначения:
- Сделать закрытый пустой список
- Если он не достигает узла назначения, рассмотрите узел с наименьшим f-показателем в открытом списке.
Мы закончили
Поместите текущий узел в список и проверьте его соседей.
- Для каждого соседа текущего узла:
- Если сосед имеет меньшее значение g, чем текущий узел, и находится в закрытом списке:
Замените соседа этим новым узлом в качестве родителя соседа.
- Иначе Если (текущий g меньше и сосед находится в открытом списке):
Замените соседа на более низкое значение g и измените родительский узел соседа на текущий узел.
- Иначе Если соседа нет в обоих списках:
Добавьте его в открытый список и установите его g
Как реализовать алгоритм A* в Python?
Рассмотрим график, показанный ниже. Узлы представлены розовыми кружками, а веса путей вдоль узлов указаны. Числа над узлами представляют эвристическое значение узлов.
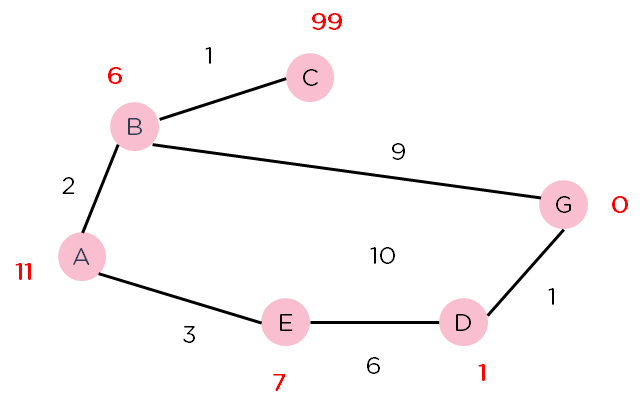
Рисунок 3. Взвешенный график для алгоритма A*.
Вы начинаете с создания класса для алгоритма. Теперь опишем открытые и закрытые списки. Здесь вы используете наборы и два словаря — один для хранения расстояния от начального узла, а другой — для родительских узлов. И инициализируйте их значением 0 и стартовым узлом.

Рисунок 4: Инициализация важных параметров
Теперь найдите соседний узел с наименьшим значением f(n). Вы также должны закодировать условие достижения узла назначения. Если это не так, поместите текущий узел в открытый список, если его еще нет в нем, и установите его родительские узлы.
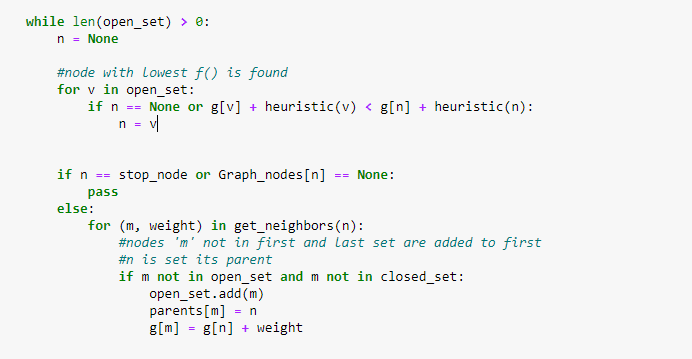
Рисунок 5. Добавление узлов в открытый список и установка родителей узлов.
Если у соседа значение g меньше, чем у текущего узла, и он находится в закрытом списке, замените его этим новым узлом в качестве родительского узла соседа.

Рисунок 6. Проверка расстояний и обновление значений g.
Если текущий g ниже предыдущего g, а его сосед находится в открытом списке, замените его на более низкое значение g и измените родителя соседа на текущий узел.
Если соседа нет в обоих списках, добавьте его в открытый список и задайте ему значение g.
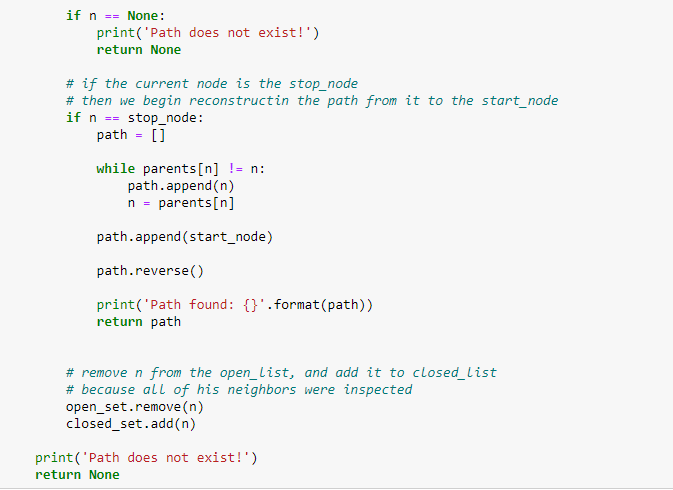
Рисунок 7. Проверка расстояний, обновление значений g и добавление родителей.
Теперь определите функцию для возврата соседей и их расстояний.

Рисунок 8: Определение соседей
Также создайте функцию для проверки эвристических значений.
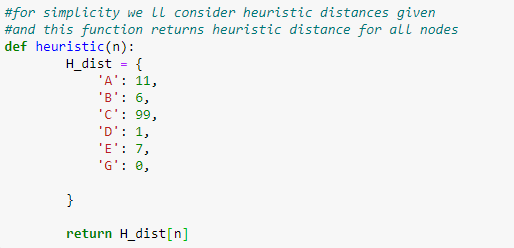
Рисунок 9. Определение функции для возврата эвристических значений.
Опишем наш график и вызовем функцию звезды.
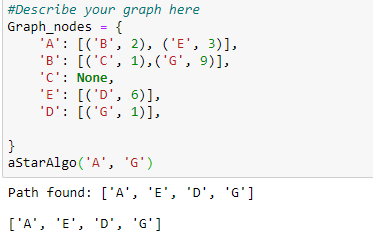
Рисунок 10: Вызов функции A*
Алгоритм проходит по графу и находит путь с наименьшими затратами.
то есть через E => D => G.
Преимущества алгоритма A*
Алгоритм A* предлагает несколько преимуществ.
- Во-первых, он гарантирует поиск оптимального пути при использовании соответствующих эвристик.
- Во-вторых, он эффективен и может обрабатывать большие пространства поиска, эффективно отсекая неперспективные пути.
- В-третьих, его можно легко адаптировать к различным проблемным областям и эвристикам.
- В-четвертых, A* является гибким и адаптируемым к изменяющимся затратам и ограничениям местности. Кроме того, он широко реализован и имеет огромное количество доступных ресурсов и поддержки.
В целом, преимущества A* делают его популярным выбором для решения задач поиска пути и оптимизации.
Недостатки алгоритма A*
Хотя алгоритм A* имеет множество преимуществ, он также имеет некоторые ограничения.
- Одним из недостатков является то, что A* может быть дорогостоящим в вычислительном отношении в определенных сценариях, особенно когда пространство поиска обширно и количество возможных путей велико.
- Алгоритм может потреблять значительные ресурсы памяти и обработки.
- Еще одним ограничением является то, что A* сильно зависит от качества эвристической функции. Если эвристика плохо спроектирована или неточно оценивает расстояние до цели, производительность и оптимальность алгоритма могут быть поставлены под угрозу.
- Кроме того, A* может иметь проблемы с определенными типами графов или пространств поиска, которые имеют нерегулярную или непредсказуемую структуру.
Что, если пространство поиска в алгоритме A* представляет собой не сетку, а граф?
Алгоритм A* можно применять к несеточным пространствам поиска, представленным в виде графов. В этом случае узлы графа представляют состояния или местоположения, а ребра представляют связи или переходы между ними. Ключевое отличие заключается в определении соседей для каждого узла, которое определяется ребрами графа, а не соседними ячейками сетки. A* по-прежнему можно использовать для поиска оптимального пути в таких пространствах поиска на основе графов путем соответствующего определения эвристической функции и реализации необходимых структур данных и алгоритмов для обхода графа.
Примеры алгоритма A*
A* успешно применялся во многих реальных сценариях. Например, при планировании пути робота A* помогает роботам перемещаться в динамичной среде, избегая препятствий. В разработке игр A* используется для создания интеллектуального ИИ противника, который может эффективно преследовать и следовать за игроком. В логистике и транспортировке А* помогает найти оптимальные маршруты доставки транспортных средств, минимизируя время и затраты. Кроме того, A* имеет приложения для сетевой маршрутизации, например, для поиска кратчайшего пути в компьютерной сети. Эти примеры подчеркивают универсальность и практичность концепций и реализаций алгоритмов A* в различных областях.
Заключение
В этом уроке, знакомящем с мощным алгоритмом поиска, вы узнали все об этом алгоритме и увидели его основную концепцию. Затем вы изучили работу алгоритма и псевдокод для A*. Наконец-то вы увидели, как реализовать алгоритм на Python.
Программа последипломного образования Simplilearn в области искусственного интеллекта и машинного обучения призвана помочь учащимся разгадать тайну искусственного интеллекта и его бизнес-приложений. В курсе представлен обзор концепций и рабочих процессов искусственного интеллекта, машинного и глубокого обучения, а также показателей производительности.
Есть ли у вас какие-либо сомнения или вопросы к нам по этой теме? Упомяните их в разделе комментариев к этому уроку, и наши эксперты ответят вам на них в ближайшее время!
Выберите правильную программу
Улучшите свою карьеру в области искусственного интеллекта и машинного обучения с помощью комплексных курсов Simplilearn. Получите навыки и знания, которые помогут преобразовать отрасли и раскрыть свой истинный потенциал. Зарегистрируйтесь сейчас и откройте безграничные возможности!
| Название программы | Инженер по искусственному интеллекту | Последипломная программа в области искусственного интеллекта | Последипломная программа в области искусственного интеллекта |
| Гео | Все регионы | Все регионы | В/СТРОКА |
| Университет | Простое обучение | Пердью | Калтех |
| Длительность курса | 11 месяцев | 11 месяцев | 11 месяцев |
| Требуется опыт кодирования | Базовый | Базовый | Нет |
| Навыки, которые вы изучите | Более 10 навыков, включая структуру данных, манипулирование данными, NumPy, Scikit-Learn, Tableau и многое другое. | 16+ навыков, включая чат-боты, НЛП, Python, Keras и многое другое. | 8+ навыков, включая Контролируемое и неконтролируемое обучение Глубокое обучение Визуализация данных и многое другое. |
| Дополнительные преимущества | Получите доступ к эксклюзивным хакатонам, мастер-классам и сеансам «Спроси меня о чем-нибудь» от IBM Прикладное обучение посредством 3 основных и 12 отраслевых проектов. | Членство в Ассоциации выпускников Purdue Бесплатное членство в IIMJobs на 6 месяцев Помощь в составлении резюме | До 14 кредитов CEU Членство в кружке Caltech CTME |
| Расходы | $$ | $$$$ | $$$$ |
| Изучите программу | Изучите программу | Изучите программу |
Часто задаваемые вопросы
1. Почему он называется алгоритмом А*?
Алгоритм A* получил свое название от двух ключевых особенностей. Буква «А» означает «Допустимый», поскольку для оценки затрат используется допустимая эвристика. «*» означает, что он объединяет фактические и предполагаемые затраты для принятия обоснованных решений в процессе поиска.
2. Каковы свойства алгоритма A*?
Алгоритм А* обладает свойствами полноты, оптимальности и эффективности. Он гарантирует нахождение решения, если оно существует (полнота), находит оптимальный путь с наименьшими затратами (оптимальность) и эффективно исследует меньшее количество узлов за счет использования эвристики (эффективность).
3. Каковы основные компоненты алгоритма A*?
Основные компоненты алгоритма A* включают открытый список для отслеживания узлов для исследования, закрытый список для хранения оцененных узлов, эвристическую функцию для оценки затрат, функцию стоимости для назначения затрат действиям и очередь приоритетов для определения порядка расширения узла на основе сметных затрат.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)




